I am splitting my free time at the moment up in “playing games” and vectrex programming.
In the last two weeks I fired up (for the first time in two years) my old World of Warcarft account – a little sad that I was greeted with a “your computer does not have the performance required” (or something in that sense).
Anyway the “power” was enough to level a new Druid to 110 and have two artifact weapons fully developed. I once entered a raid – but there I discovered for real that my computer seemingly had some “power” loss in the last two years…
Also Season 11 of Diablo started – I leveled a new seasonal Monk and a Necromancer to level 70, did some equipment runs and are now at Paragon 270 or so…
… eh … yeah, Vectrex…
Seemingly all is still the same, unseemingly I spend quite a lot of time with the tile system. Did a complete new “engine” and rewrote all clipping routines. I guess I invested about 30h in that (my – time flies).
I will show no new screenshots of that, since the map is basically the same and as a user you do not see a difference.
In short this is what happened:
- programmed a level “compiler” that uses as input the old level, and outputs “reduced” direct level data, that can be used by the new tile engine. You might have seen in the Vide-blog, that I used the scripting abilities of vide to translate the level data while doing an assembler run.
- new tile engine display (more on that further down)
- New homogen clipping routines. For performance reasons clipping is done differently for each direction (right, left, top, bottom). Each direction also has 3 different clipping routines -> 3*4 = 12 clipping routines.
(More … the further below)
Clipping
The tiles for the engine can come in different types, as of now I am thinking about these:
- simple
- exponential
- exact
- – and above combined with a “multi tile” flag
For the clipping routines only the first 3 types are important.
Simple
Simple clipping – here each x, y pair of coordinates in a vectorlist must have one of its values zero. If this is the case clipping can be done WITHOUT any divide – this is the fastest possible clipping version. To easily recognize those tiles, think of them as rectangles!
Exponential
Exponent clipping – here each vector of a list has a 2 “exponential size”, the strength must be one of 2,4,8,16,32,64,128 sizes (127=128). If these criteria are met, division within the clip routines is done via “easy” asr…
Exact
Exact clipping – all vectors can be clipped regardless of any size/position (only used atm for the second corner clips), this is by far the slowest since a custom division routine must be used.
Clipping at the moment ist done using “pattern” vectorlists, the routines expect a “from” list pointed to by “X”-register, the result will be written to the memory pointed to by the “U”- register. The output list is also a pattern vectorlist, and can thus be clipped again (corner tiles).
Note:
The result list, when drawn must be drawn at the same position as the original, also it has the same dimensions. All the clipping does is use pattern information to “hide” parts of the vectorlist. The resulting list always consists of the equal or larger amount of vectors!
As a general rule of thumb to clip one line the clipping takes about 100 cycles (some more, some less).
Tile engine
As a preface:
While the current implementation uses the third of the last engines memory imprint and is (without all optimizations [especially multi tiles] switched on) about 6000 Cycles faster than the last proto – I still deem it (slightly) to slow. The overhead of the engine itself (the parts that are not vector moving, vector printing and clipping) still is about 5000-6000 cycles and thus to costly.
Anyways these are the features of the current implementation:
Level information
1. a list of “row” addresses (word pointers to memory locations) – with such a list the y-position within the tile map can be easily calculated
2. each row has the format (thus a list of tiles in one row):
dw addressOfNextLine, TILE_INFO1, TILE_INFO2, … , TILE_INFOn, -1
The TILE_INFO consists of:
– db xPos [position of tile on the tile map “grid”]
– dw tileDefinitionAddress
– db xPositionInTileMapAfterPrintingThisTile
Only tiles are kept in the definition, empty “spaces” are left out. The drawback is, the x position in the tile map can not be calculated, but the engine must loop thru all previous x-tiles to find the current x-position.
MAKE SENSIBLE LEVELS!
Drawing
1. The drawing is split into 3 parts:
– top row (only here top clipping is needed)
– center rows
– bottom rows (only here bottom clipping is needed)
The splitting up saves some checkings.
The top/bottom row of tiles is printed seperately, since here all tiles (in general) must be clipped.
The clipping of tiles is done using clipping buffers. There are three such buffers, a vertical buffer, a left buffer and a right buffer. If two consecutive tiles are the same (tile vectorlists have unique ids), the clipping is clever enough to recognize that the buffer is already filled – and no additional clipping is done. The clipping is done while the “moveTo” of the to be printed tile is waiting, but the clipping usually takes much longer than the move-wait.
Center tiles (tiles which do not need top/bottom clipping) are handled differently, although these tiles too may need clipping (left/right) most of these tiles don’t. To use the moveTo wait efficiently I implemented a “look ahead” feature, that prepares the handling of the next tile.
Multi tiles: Usually a tile has a fixed size, the width is that of one column and the height that of one row within the “grid” of the tilemap. Multi-tiles can have a larger width. If you look at the last posted video you will see that the level definition features “blocks” that consist of three tiles, one tile in the shape of a “[“, one “]” and in the middle one shaped like a “=” – together building a three width “block”. That block can be realized with a single tile (consisting of a vectorlist, that describes the shape) and being defined as a multi-tile with a width of 3.
This displayed looks roughly like: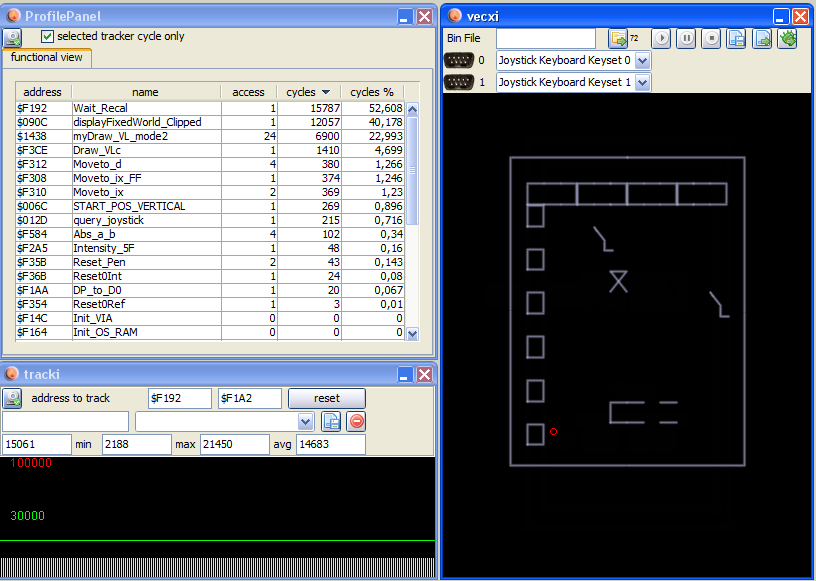
Non – clipped this is ok, but notice the 4 “blocks” in the top row. 4*3 = 12 tiles that will be clipped as soon as scrolling starts. Buffering will not work, because buffering only works with consecutive equal tiles. Thus doing one scroll up takes EXTREMLY longer:
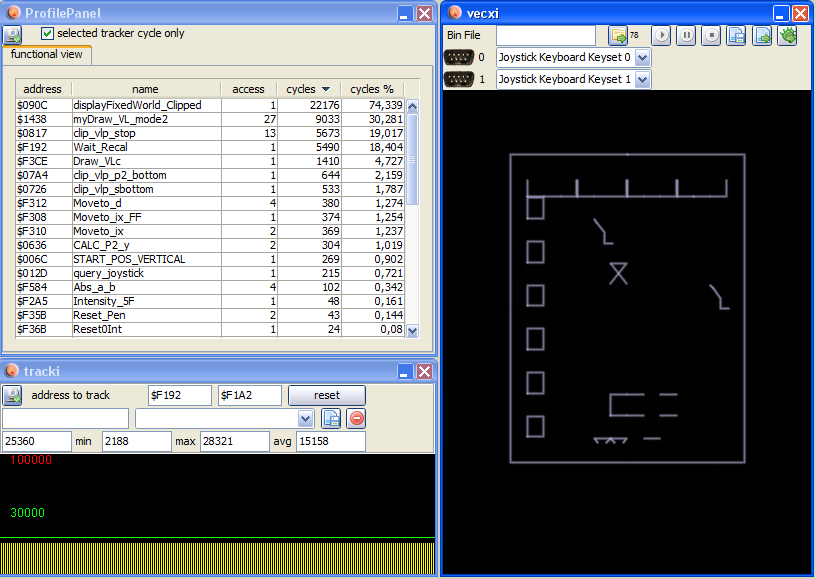
There are several reasons:
a) 3 additional tiles in the bottom row
b) the 3 tiles in the bottom row mus be clipped
c) One of the tile in the bottom row is not “simple” (clip routine is: clp_vlp_sbottom) but “exponent” (clip routine is: clp_vlp_p2_bottom)
d) each (EACH!) tile in the top row must be clipped 3*4 = 12 (never mind the displayed 13, the 13th is the right most tile that is not displayed, internal stuff) (clip routine is: clp_vlp_stop)
Same scenario using multi-tiles in the top row:
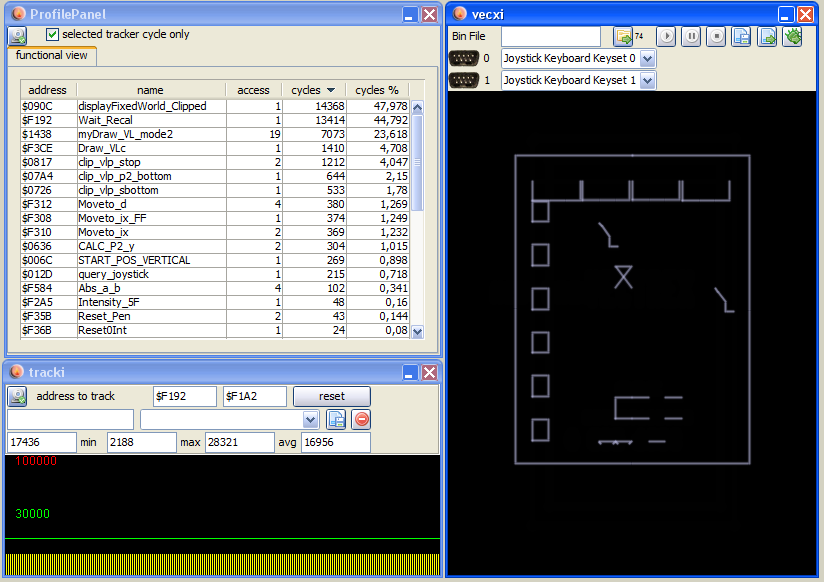
Not only is there a saving because of 4 saved “moves”, there is a saving since only 4 tiles must be clipped in the top row AND those 4 tiles are the same, so the clip buffer kicks in. So using a multi tile in this scenario saves over 8000 cycles per draw.
My target still is that a “level” must be drawn in all positions with less than 20000 cycles. With above optimizations and clever level building I think it is possible!
There still is more testing todo, enhaning of the “engine” to do animated tiles and searching for clever ideas to do more optimizations.
There were several other optimization ideas which had to be thrown into the bin already, but in my Diablo- and WoW- free time clever new ideas might still spawn. Sometimes it is best to do something completely different and relax. I am doing that just now :–)
Quote: “….I think it is possible!…..”
phew 😉